Twitter is a great social media platform, and your timelines stay relevant depending on how much you tweak the list of people you follow. I primarily use Twitter to read content that others have curated and reviewed. It saves me a lot of time and points me to a lot of content I didn’t know existed.
One of the problems with Twitter is that over time, your timeline may be flooded because you are following people you no longer need to. It is easy to get inundated with content on Twitter and therefore optimizing your timeline by pruning the list of people you follow is as important as spring cleaning. Many “influencers” will follow you in an attempt to get you to follow them back. Then over time, they will unfollow you leaving you with their content to read while they never read the thoughts you share. Waning interests, changing hobbies, old technologies being replaced with new ones, stale accounts, decommissioned handles are all the more reason to keep tidying up the list of people you follow.
Here is a tool and data approach I take to clean up the people I follow regularly.
Download the Twitter CLI available here. This is one awesome project.
Follow the instructions for installation on the git page depending on the platform you are running on.
Follow the instructions to register a new app with Twitter, set the permissions to “Read, Write and Access direct messages“.
Using the command `t authorize`, login to Twitter and authorize the Twitter CLI to operate your Twitter account.
Now you can start dumping data from your Twitter account on the command line and figure out the accounts to unfollow.
Here are some tricks I utilize to extract some insights from the Twitter CLI dumps:
Leaders are the accounts I follow but they don’t follow back. I have found that pruning this list keeps my timeline sane.
t leaderslists the leaders who you follow.
Since Last tweeted at Tweets Favorite Listed Following Followers
...
t leaders -l -a -s=tweeted
The above command will give you all leaders and the time since they tweeted in sorted order. Leaders who have not tweeted in a while are good candidates to unfollow. You will find them on the top of your list.
t leaders -l -a -s=tweets
The above command will list all leaders with their tweet count in sorted order. In this list, look towards the top and the bottom of the list. The top will have leaders who have not tweeted much and the bottom has those who tweet a bit too much. Pruning by unfollowing from either ends of the list will help you cleanup your feed.
t leaders -l -a |grep -i "moved\|no longer\|instead"
The above command will list a few potential Twitter handles that are no longer used. You need to review the list and if some handles have moved, it is a good idea to clean them up.
t leaders -l -a -c >out.csv
The above command will output the leader list in CSV (comma separated value) format. You can then open the file in a spreadsheet program to slice and dice it further. For example, you can view only the leaders who are not verified accounts. You are most likely to find a few accounts in this list you’d want to unfollow.
Unlike other social media types, Twitter needs regular pruning for it to continue to be a useful medium for curated content. Cleanup keeps the content relevant and meaningful thereby reducing the signal to noise ratio.
I am an avid vim user. I have used GVim on Windows and now I use MacVim on Mac. I also use it from the terminal when I need it. There are many reasons why I love vim but this post is not about that or a tutorial on vim. If vim is your editor of choice, you will enjoy this series as I will share “why” my vimrc looks the way it does.
I have read that many folks prefer a standard out of the box tool and don’t like customizing it. I, on the contrary, like to configure vim to my exacting needs. My vimrc is a result of my ideas and a number of copy-pastes from fellow vimmers who have shared their configurations over the internet.
Managing the vimrc file.
In this first part, I talk about the vimrc file itself and some tips to manage it.
Make vimrc always available:
Your first goal should be that when you set up a new computer, you should be able to configure your favorite editor in the least amount of time. Most of my settings and plug-ins are in my vimrc file. I install all plug-ins through a plug-in manager (more on that later).
To be productive in the shortest amount of time, I require my vimrc to be available to me ASAP. I achieve this through the following ways.
I publish my vimrc to a public github.com repo. Make sure you remove proprietary stuff that you don’t want to share from the file before submitting it in your public repo.
My vimrc is located within my data folder – a folder that contains stuff I care about. This data is regularly backed up. So, even if I don’t have access to github.com, I usually do have my vimrc available to me through the backup.
I don’t use the vimrc in the default location. I always sync the file to a folder such as ~/config and then I modify the default vimrc file and source the file that I synced.
cd ~git clone https://github.com/technochakra/config.gitecho so ~/config/vimrc > ~/vimrc
Configuration is code.
As noted above, I check-in my vimrc file to github. If you are a software developer, we have reached the age where code, infrastructure, configuration should be treated as code and regularly checked in. vimrc falls squarely in that category as well.
Reconstructing your vimrc file from scratch is painful and should not be done.
Avoid the defaults:
I realized recently that my vimrc file contained some obvious defaults. If you look at the help of a setting and it defaults to what you need, you don’t have to have it in your vimrc file unless some plugin is overriding your defaults.
help errorbells
In the example above, errrorbells (a beep in case of an error) is off by default. So, your vimrc file does *not* need the following line.
set noerrorbells
Having a minimal vimrc file makes it more manageable and it takes you less time to figure out the setting when you revisit it after a few years.
Source vimrc as soon as you write it
The following command sources my vimrc file as soon as I modify it. This helps me try out my changes immediately, fix errors right away and gives me a vimrc file that always works. It is also very satisfying to see your settings take effect immediately.
autocmd bufwritepost vimrc source ~/config/vimrc
This does not work when I modify the plug-ins I use but I’ll cover that later.
Lint free vimrc
As noted above, I like to treat my vimrc file like code. Well, then there is no excuse not to statically analyze it for warnings and errors. I use vint as my lint program. For some reason, vint didn’t work on MacVim when called from plugins that integrate with it so I ended up using vint from the command line.
vint ~/config/vimrc
Sample output:
<some_path>/vimrc:1:1: Use scriptencoding when multibyte char exists (see :help :scriptencoding)
vint is a great tool to avoid common mistakes. For example, I did not know about augroups until the tool flagged them for me.
<some_path>/vimrc:31:3: autocmd should execute in an augroup or execute with a group (see :help :autocmd)
<some_path>/vimrc:32:3: autocmd should execute in an augroup or execute with a group (see :help :autocmd)
It turns out that by putting autocmds in an augroup, and clearing the augroup using the autocmd! command, you prevent duplication of autocmds in your augroup when your source the file again. This keeps things clean and optimal.
augroup NERDTREE
autocmd!
autocmd vimenter * NERDTree
augroup END
Managing your vimrc file is fairly simple. It helps to constantly clean it up and keep it minimal. Now that we have the structure for maintaining our vimrc file, I will discuss the settings I use in subsequent posts.
Caution: Consider executing the steps below only if you are sufficiently technical. The steps may be risky and can lead to loss of your data so please don’t try them if you don’t understand them.
A WordPress blog consist of three main parts – the content, the WordPress software and the hosting provider on top of which it runs. You are responsible for the content, the server capacity is rented out by the hosting provider and you install WordPress on the rented server. Recently I switched my shared hosting provider and the last thing I wanted to do was lose all the content and the settings on my blog. Here are the 10 steps it took me to switch hosting providers with little or no downtime.
Step 1 – Understand the basics!
The first step is to understand what we are dealing with. WordPress is a Content Management System. This means the software will take your content and render it as per your liking. The content portion of your blog is stored separately in a MySQL database. The rendering portion of the software is WordPress itself but may also consist of tweaks you may have made over time to the theme and settings.
So to backup from one hosting provider and restoring on another requires you to save the WordPress installation and also the underlying MySQL database.
Step 2 – Backup Your Site
You should always switch to a new hosting provider while access to the existing one is still valid.
Backup your site in as many ways as possible. This creates redundant backups which are great to have if things go wrong. The first manual step is use a good graphical FTP program, SFTP to your site and download everything you can. I mean everything in your home directory even if it sounds like a bad idea.
Now look for backup solutions your hosting provider may have. A common one is creating backups using cpanel. This lets you download a compressed backup file of your entire home directory. Some hosting providers may remove this option or ask a separate fee for it so get in touch with your hosting provider but don’t tell them yet that you plan to move away.
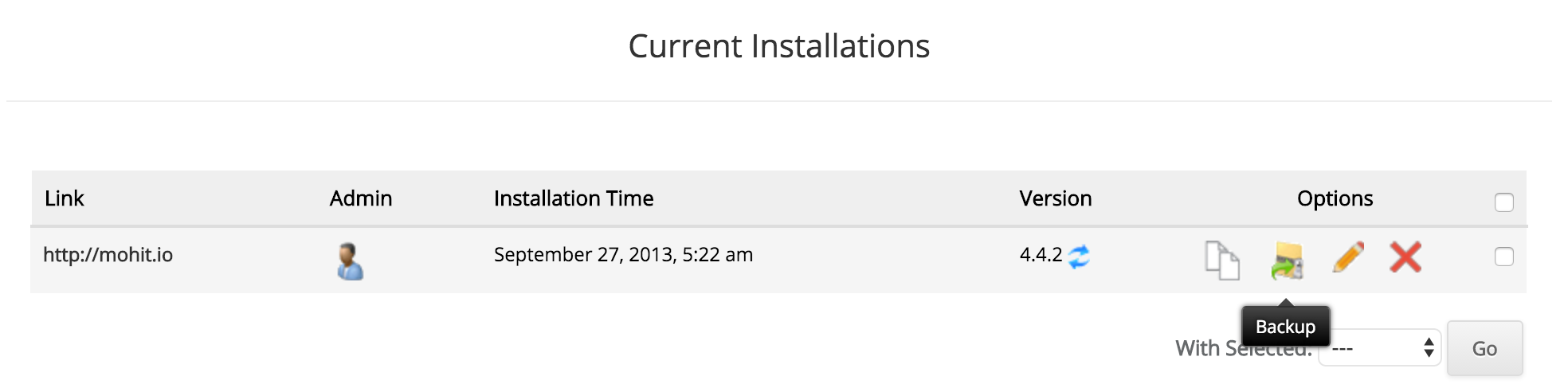
Another option is to use installation software such as Softaculous to create backups of your WordPress installation. Steps are outlined here. Make sure you backup both your installation and your database.
Softaculous
Option to backup from within Softaculous
The idea is to get as many copies of your data as possible.
Step 3 – Create a phpMyAdmin backup
The content of the blog is stored in the MySQL DB and you can use phpMyAdmin to create a backup of your database. This may sound redundant but don’t skip it as it is an important step to successfully import your data to your new hosting provider. The steps are as follows –
Access cpanel (http://<yoursite>/cpanel) and click on phpMyAdmin.
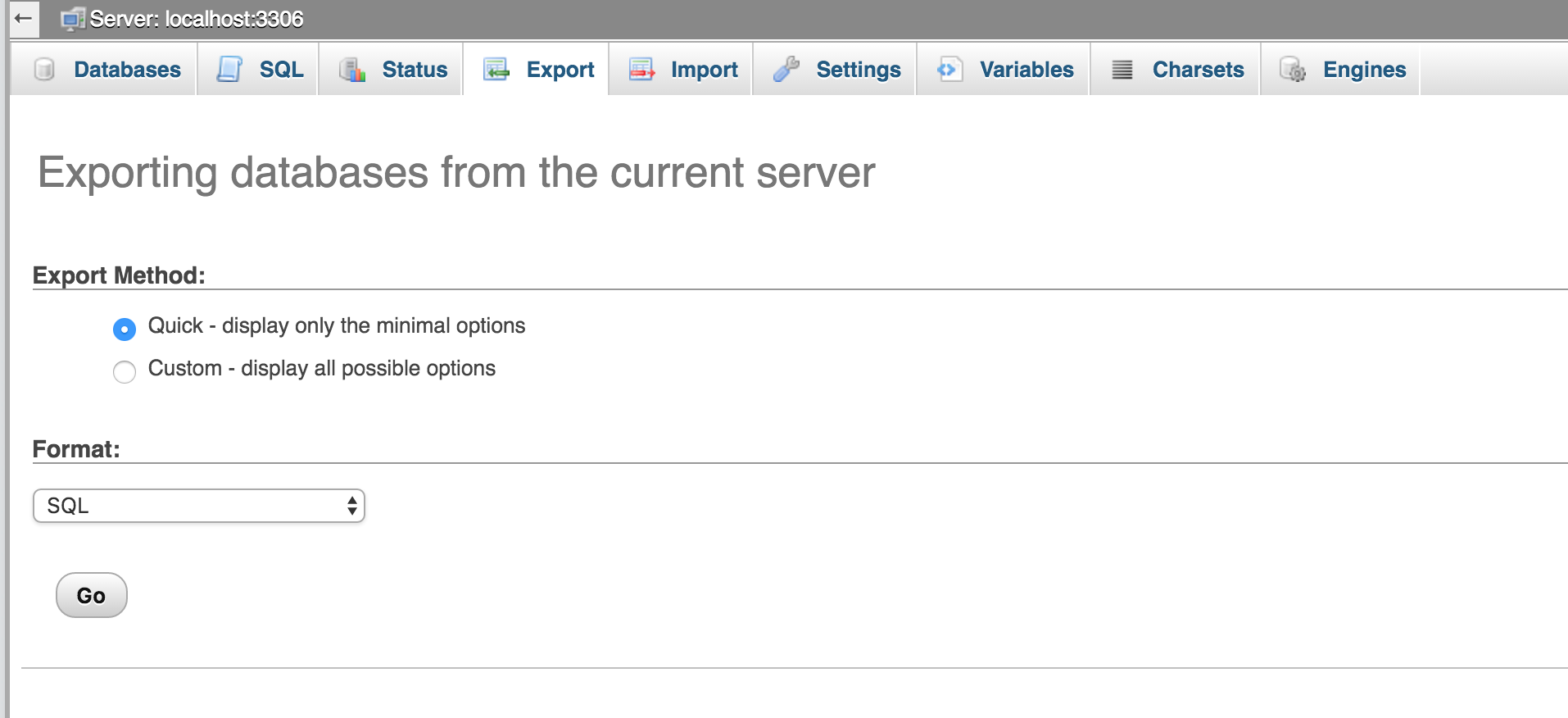
Goto the export tab and export your database with the default options.
A text file will be downloaded on your machine.
Open the backup file in a text editor and search to see if your blog content is in the backup file or not. If the backup has your content, your database was successfully exported.
Exit the editor and then create multiple copies of this file to create redundant backups.
Step 4 – Install WordPress on new hosting provider
Goto cpanel or whatever your hosting provider uses to install a fresh copy of WordPress. We will be overwriting this copy with our backups later.
Note all the credentials you created during this step and store them in a secure location.
Step 5 – Restore the look and feel of WordPress.
Goto your backups and locate your wp-contents folder.
Connect to your hosting provider using SFTP and look for the wp-contents folder on the new hosting provider.
Overwrite the wp-contents folder with the backup. I prefer to rename the wp-contents folder to wp_contents.old and then upload from the backup.
You may also have to edit the wp-content.php file. This file sits alongside the wp-contents folder and should only be hand edited and not overwritten from the backup. I had to port the changes from my backup to the file on the hosting provider as I had changed the table_prefix in my previous installation. To make the same MYSQL database work, the new installation also needed the same tweak.
If you had a favicon.ico file (the small icon that browsers show in the tab for your site) you should upload that too.
Step 6 – Restore the MySQL database using phpMyAdmin
Login to phpMyAdmin on your new hosting provider. I use cpanel to launch phpMyAdmin and was aware of the user credentials required for the login. This may require some help from the support chat of your hosting provider in case you run into login issues.
In the databases tab, click on the WordPress database. If you haven’t used your new hosting provider much, there should only be one database to choose from.
The above link will open up the structure of the MySQL database you created when you installed WordPress.
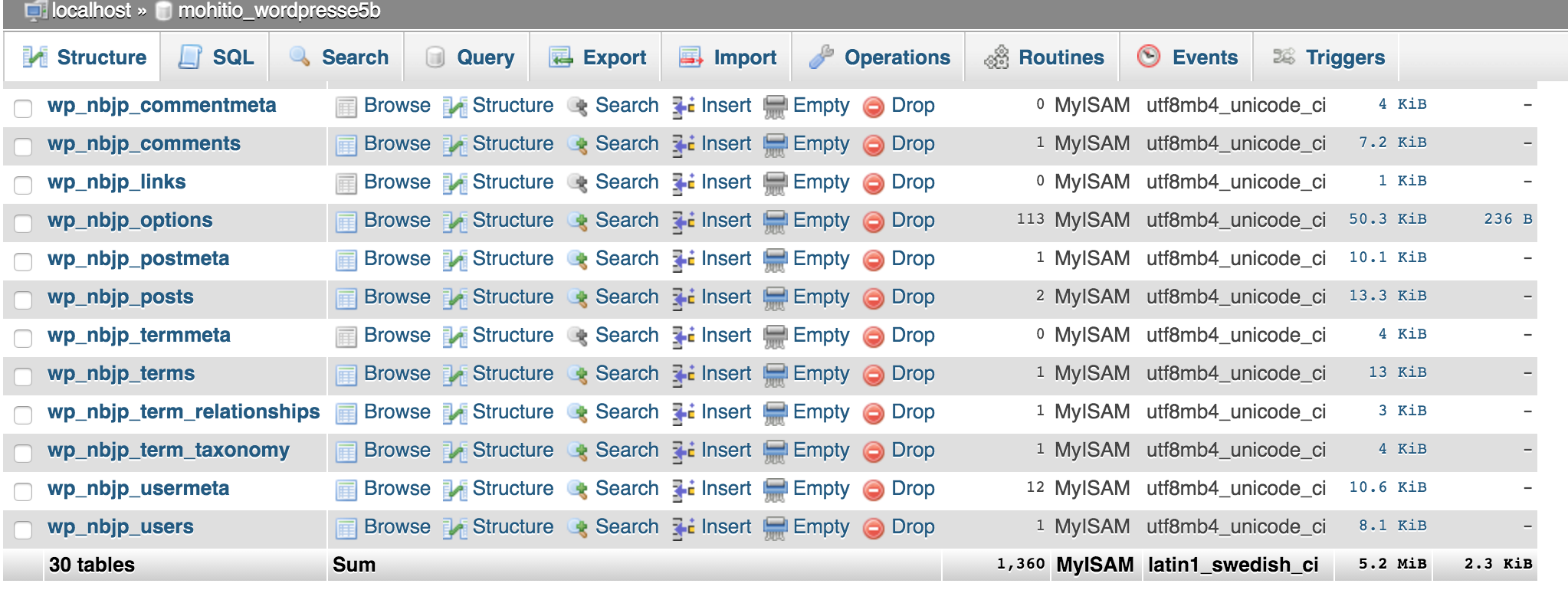
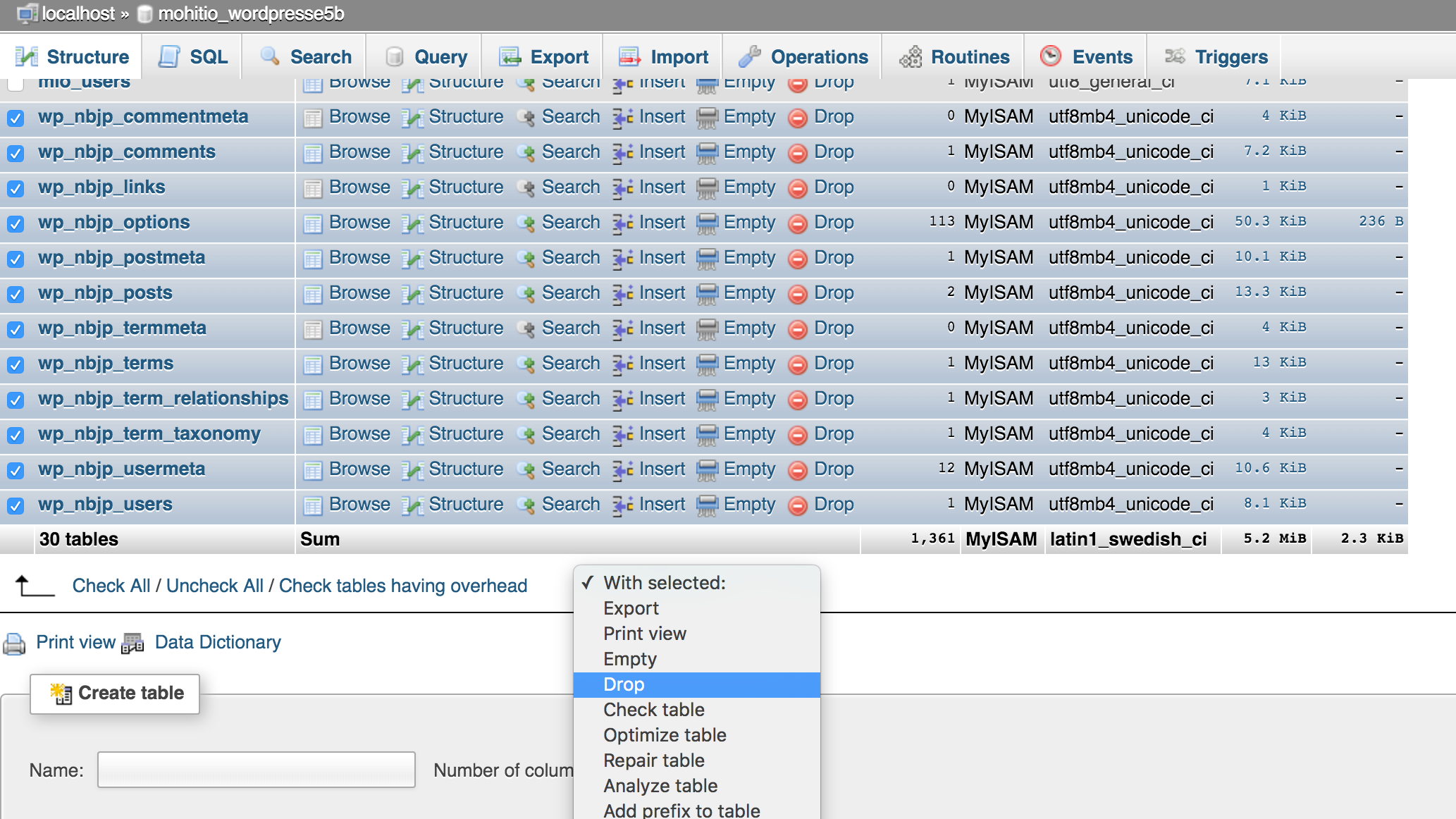
This database has no data yet and we will drop all tables from it. Select all rows and select Drop. This will delete all tables from your database.
Now go to the Import tab and import the backup file on your local computer that you downloaded using phpMyAdmin earlier.
If everything goes well, you are almost done.
Step 7 – Update name servers
Name servers resolve your domain names to the IP address of the server provided by your hosting provider. Your domain name settings should now be changed to point to the name servers of the new hosting provider. This setting can be done through the interface you use for managing your domain name.
It make take a few hours for this to propagate.
Step 8 – Test your website
Using the whois command make sure your domain now points to the new hosting provider.
Goto <your_site>/cpanel and the cpanel of your new hosting provider should open up. This means your domain is pointing to the new servers assuming your hosting provider does have cpanel support.
Your site should work as earlier. If you see a blank page you will need to find out what is going wrong.
Right click in browser and view source. If the source is blank, something may be wrong with your theme setup.
Goto your_blog/wp-admin. Sometimes the themes have errors in them but the admin page may work fine.
Access logs on your remote server and try to make sense of what went wrong.
Now check links in your blog to see nothing is broken.
Tweak your blog settings till you fix the problems you encounter.
Update any plugins or themes through your administrative interface.
Activate plug-ins you need in your new installation. Don’t enable all plugins but only the ones you need. It helps the responsiveness of your site and reduces security risk of your application in case a plugin becomes vulnerable in future.
This is the step where your hard work either pays off or you need to start again and give it a few more tries. As each installation is a unique snowflake, it is difficult to list out detailed steps on what could have gone wrong.
Step 9 – Secure Your Site.
When you move WordPress, you may have forgotten the tweaks you did earlier to secure your site. For example, in my new installation, I forgot to disable directory listings and later had to add the following line in my ~/public_html/.htaccess file to fix this.
Options -Indexes
It is important to validate security of your WordPress site. I use WPScan to test my installation and even though I thought I had installed everything correctly, WPScan identified a couple of misconfigurations I had missed.
After fixing your issues, make sure your blog links continue to work.
Step 10 – Submit a cancellation request with your old hosting provider
After making sure everything works and data has been successfully migrated, submit a cancellation request with your old hosting provider. Or else the hosting provider may auto-renew your membership and charge your credit card.
Conclusion
The above 10 steps worked for me to move to my new hosting provider after having been with the earlier one for 5 years. I only need to track my cancellation request with the old hosting provider.
Keep backups, reserve sufficient time to switch between hosting providers and understand every step you take if you want to be successful with moving your blog. As blog migration takes time and has some risks, first think through the reasons why you want to move your blog to a new hosting provider before undertaking the project.
fs_usage is an OS X command line utility that shows the network and file access operations that are happening on the operating system. This is a handy utility when you want quick answers without firing up your debugger.
The Problem
For example, recently I ran into a problem where my data files for Outlook client on Mac had become corrupt. My solution was a simple one – delete all the data and Outlook profiles and let Outlook sync from the server once again. Deleting Outlooks files is not always a solution but in my case it was because I had everything on the server.
Now even after deleting all of the Outlook files under ~/Documents/, Outlook kept doing busy work without opening up my mail and it wasn’t able to repair my setup.
I wanted to quickly find out what files was Outlook still accessing so that I could delete them on my own and setup my mailbox from scratch.
This is where fs_usage came very handy. This command is equivalent to strace on Unix/Linux and procmon on Windows. All these tools trace file operation system calls and display it to the end user. As fs_usage (or file system usage) is a privileged command, you need to have root access to execute this.
An Example
Following are the steps to trace the filesystem operations on a Mac –
1. Get root access on the command prompt.
$ su
Password:
2. Find the PID of the process that you want to trace. Skip this step if you want to trace all file system calls for the operating system.
$ ps -A |grep Outlook
1888 ?? 120:04.41 /Applications/Microsoft Outlook.app/Contents/MacOS/Microsoft Outlook
2878 ttys001 0:00.00 grep Outlook
Above 1888 is PID of Outlook on my machine.
3. Use the PID you got from step 2 with -f "pathname" option to display pathname operations for the process you are monitoring.
Under the Users/xxx/Library/Group Containers/ directory, Outlook is accessing profile files under a difficult to guess folder name. Deleting the files in this folder did fix my issue and I could setup Outlook from scratch.
Conclusion
fs_usage --help displays the various options that go with -f. Above, -f applies a pathname event filter. You can apply similar filters to show network, filesystem events.
fs_usage is a handy utility to know of. It is really useful when you need to observe the behavior of applications on your OS X machine without running an actual debugger.
Twitter is an indispensable tool that keeps you up to date with the latest trends and news in your domain of work. I’ll be using my blog to share a few tips and tricks I have learnt over the years.
Tweets are a steady flow of unscheduled packets of information on your timeline and it is not always possible to read every single one of them. Unlike an email inbox, it is best to discard unread tweets if you are unable to view tweets for a couple of days.
There are always some Twitter accounts you’d like to track
There are a few accounts whose tweets you may not want to miss even when you don’t have time to monitor your twitter account.
For example, I like to follow tweets from –
The company’s twitter account (or sub account) to stay tuned with the business and RT if something catches my eye.
All team members who I work closely with.
All accounts that use twitter to alert their customers about delays / failures in their service or have breaking announcements. These are super critical alerts I care about such as delays on my commute routes, security alerts for software I care about, etc.
Tweets from close friends and family with whom I like to interact with.
Mobile Notifications
This is where Twitter’s mobile notification feature comes handy.
Turn on notifications and get alerts on your mobile phone whenever the account you care about tweets. Twitter will send regular mobile alerts on your smart phone and these alerts are *not* sent as SMS messages.
You will be notified on your phone / tablet and you can immediately read the tweet and react to it.
The notifications are sent even if you were not mentioned in the tweet.
In order to use this feature, you should be following the person for whom you’d like to set an alert.
The image below shows how to turn on mobile notifications for accounts you follow. Click it to view in a new window.
I have been using this feature ever since it was launched. It helps prioritize tweets you want to read without the fear of following too many people or being away from your twitter account.
So if you are looking for some sanity within the chaos called Twitter, this is a must have feature that you should try out.
You can collect a lot of useful information about an application’s backend services by observing the network connections it makes. For example, you can find out whether data is being sent to the back-end service securely over TLS or is sent as clear text.
It is relatively easy to monitor network traffic on a PC or a laptop using a network interface sniffer but for a mobile device it can get a little tricky.
The article explains the steps to capture network traffic of a mobile device using Windows 7 (and above) by creating a rogue WiFi access point . We then use existing free tools on the PC to analyze the captured packets.
Step 1: Configure A WiFi HotSpot (access point)
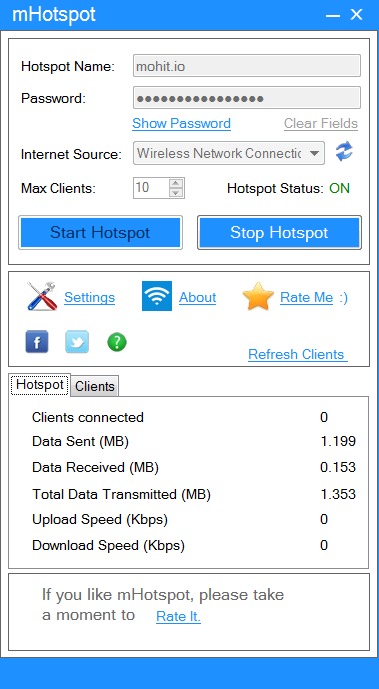
Windows 7 (and above) allows setting up an access point using the “Microsoft Virtual WiFi Miniport Adapter”. However I found it much easier to set up the access point using a third party software called mHotspot which uses the Microsoft Virtual WiFi Miniport Adapter underneath but greatly simplifies the setup process.
Enter the access point name in the “Hotspot Name” field.
Enter a “Password” value. This value will be the password a device will need when connecting to this access point.
Select an “Internet Source”. If you are connected using a cable select “Local Area Network”. If you are on a WiFi network, select “Wireless Network Connection”.
Click on the “Start HotSpot” button.
Create an access point using mHotspot
Step 2: Connect Device
Connect your device (iPad, Android phone, etc) to the WiFi access point as you would connect to any regular wireless network. The password required to connect would be the same as specified in step 1.
Step 3: Launch WireShark
By creating an access point, we are asking the device to connect to the PC and then the PC in turn routes the traffic to the internet. Therefore, by capturing the internet traffic on the PC, we can observe the connections the mobile device makes.
What we want to do here is to make sure we *only* capture the traffic from the mobile device and not every internet packet on the wire including packets originating from the PC itself.
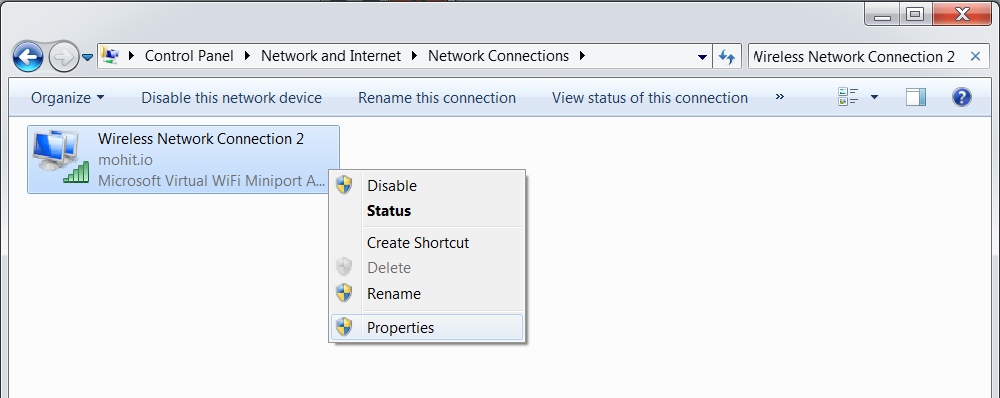
Goto Start -> Control Panel -> Network And Sharing Center -> Change Adapter Settings
Right click the connection that says “Microsoft Virtual WiFi Miniport Adapter” and click “Properties”. It will also have the name of the access point that you created above.
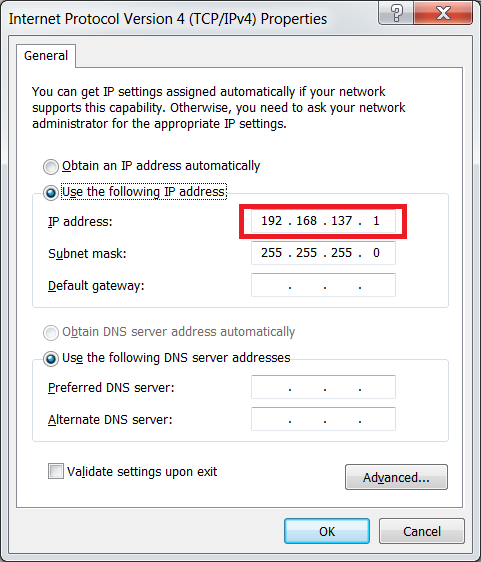
Select “Internet Protocol Version 4” (or Version 6 if you use IPv6) and click the “Properties” button. Note the IP address of the interface.
Launch WireShark. You can download a free copy from here.
In WireShark, go to Menu -> Capture -> Interfaces and select the interface with the same IP address that you noted for the virtual WiFi miniport interface above. Make sure to deselect all other interfaces in the dialog.
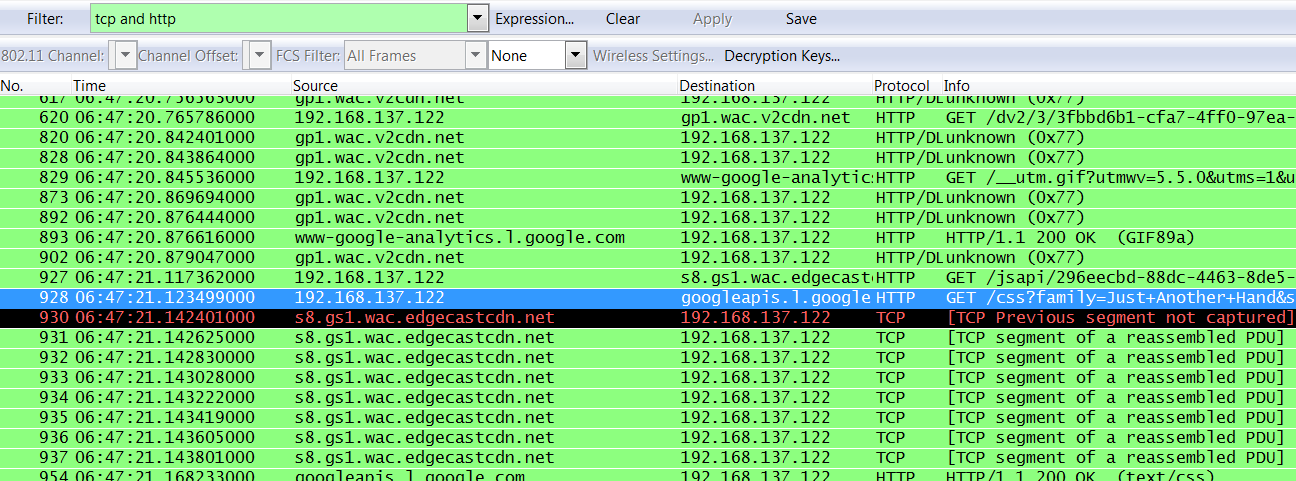
Click the Start button to start capturing traffic. Wireshark will now capture all network traffic for the rogue access point only.
Once you are done with the capture, quit WireShark and save the captured packets as a *.pcap file.
Step 4: Analyze Traffic Using Network Miner
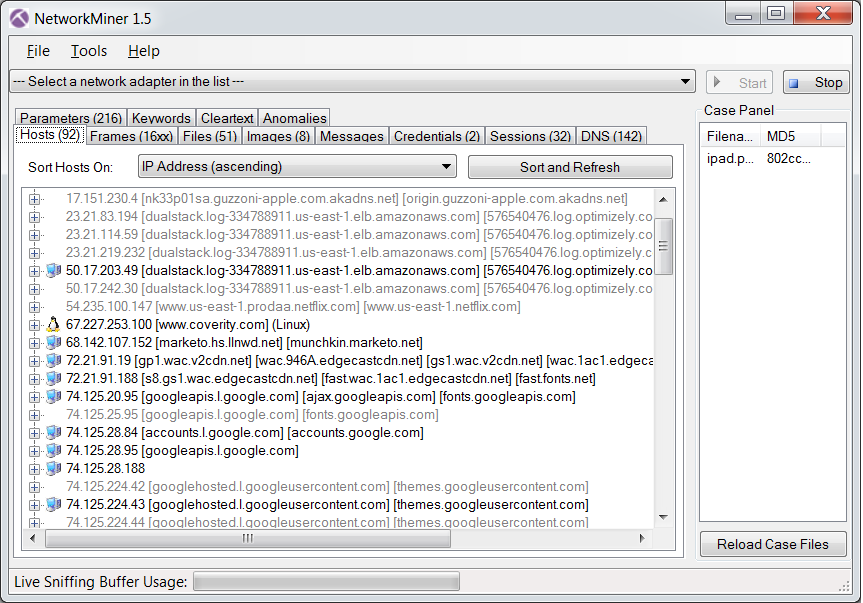
Launch Network Miner. A free version is available here.
Network Miner takes the captured data saved from WireShark and helps in easy analysis. You can also analyze the packets using WireShark.
Conclusion
A rogue WiFi access point can be used to capture network data from any device that connects to it over WiFi and is not limited to mobile devices only.
For example you can use the same trick to capture the network traffic when your Nintendo Wii talks to NetFlix over the internet by connecting the device to the rouge access point.
This trick is handy both while debugging applications or while performing a security review.
This is also a very good reminder why you should never connect to untrusted access points that might also be doing something very similar.
With the latest version of gdb (version 7 and above), one can easily map the source code and the assembly listing. The /m switch when used with the disassemble command gives the assembly listing along with the source code when available.
(gdb) help disassemble
Disassemble a specified section of memory.
Default is the function surrounding the pc of the selected frame. With a /m modifier, source lines are included (if available).
A sample listing of the disassemble command with the /m switch is pasted below:
This article introduces the basic commands required to debug assembly language in gdb.
Note: If you would like to understand an assembly language listing, jump to this article first.
Disassemble
The disassemble command provides the assembly language listing of a program and works even when a program is not running. The command works for a function name / an address / an address range.
disassemble function_name disassembles the function called function_name.
disassemble main
Dump of assembler code for function main:
0x00401180 <main+0>: lea 0x4(%esp),%ecx
0x00401184 <main+4>: and $0xfffffff0,%esp
0x00401187 <main+7>: pushl -0x4(%ecx)
0x0040118a <main+10>: push %ebp
0x0040118b <main+11>: mov %esp,%ebp
0x0040118d <main+13>: push %esi
0x0040118e <main+14>: push %ebx
------8<---------<snip>---------8<---------------
The disassemble command can also be used for a specific address.
disassemble 0x0040120f
At times the disassembly listing of a function can get very long and to limit it, an address range can be provided as shown below.
disassemble <from_address1> <to_address2>
disassemble main main+20
disassemble 0x004011ce 0x004011f7
Developers who have debugged in assembly on various debuggers on the Windows platform may prefer the Intel instruction set instead instead of the At&T set which is the default in gdb. The listing can be changed to use the Intel instruction set instead by setting the disassembly-flavor.
set disassembly-flavor intel
disassemble
Dump of assembler code for function main:
0x00401180 <main+0>: lea ecx,[esp+0x4]
0x00401184 <main+4>: and esp,0xfffffff0
0x00401187 <main+7>: push DWORD PTR [ecx-0x4]
0x0040118a <main+10>: push ebp
0x0040118b <main+11>: mov ebp,esp
0x0040118d <main+13>: push esi
0x0040118e <main+14>: push ebx
-----8<---------<snip>---------8<--------------
Controlling The Flow Of Program Execution
An instruction breakpoint can be set at a particular address using the breakpoint command.
breakpoint *0x0040118d
Take note of the asterix just before the address above.
To step into the assembly language one instruction at a time use the command:
stepi
Note that this will step into function calls that the program encounters.
To step over a function call, one can use the command:
nexti
To return from a function call that one is current stepping through, use the command:
finish
Gathering Information
To know about the values of the registers of the program being debugged use the following command:
info registers
$pc holds the program counter and it can also be used to find the instruction that will be executed next.
x/i $pc
0x40124e <main+206>: mov eax,ebx
Similar to regular debugging, the backtrace command prints the callstack.
bt
To get a list of the shared libraries that are loaded for the current program being debugged the following command is handy to use:
Performance issues usually take the longest to resolve and require a lot of patience, luck and testing iterations before a satisfactory outcome is reached. Performance tuning is a part of most development projects that have a substantial code base or do a very CPU intensive job.
This article provides few basic tips that development and testing teams can perform to reduce the time required to resolve such issues.
Reproduce The Performance Issue
Well this is true for any bug but more so for performance issues. Time reported in an original bug report may not necessarily match with that on a tester’s machine which in turn won’t necessarily match with that on a developer’s machine. These numbers depend on the state of a machine, the hardware used and the version of the software being used to report the problem.
Therefore it is important to recalibrate the numbers with the latest sources and see whether the percentage of degradation reported matches with the original bug report or not.
Find A Build Or Change That Introduced The Issue
A performance issue does not necessarily require intense profiling to arrive at the cause of the issue. At times it is important to be able to identify the build number or the change in source code that has caused the degradation. Knowing a range of changes or the exact change that caused the degradation amounts to solving half the problem.
The maximum time taken to resolve performance problems is finding the bottleneck and the rest goes into solving the problem itself. A profiler is not the only quickest means to find the bottleneck. The testing team can easily identify the build where the problem was first introduced. Likewise, the development team should try to narrow down on the exact source change that introduced the problem.
Use Release Builds Only
Do not compute performance results or perform investigations on a debug build. With optimizations turned off and extra debug code, numbers from debug builds are neither accurate nor reliable.
The reason many teams use the debug build is because the profiles generated using debug symbols look more meaningful to them as programmers. Use a release build with debug symbols instead.
Use The Same Machine
If you are comparing performance between two different versions, use the same machine to compute the numbers. This ensures that differences in processor speed, state of the machine, etc do not play a role in the difference in timings.
Catch Issues Early
The testing team should regularly run performance tests and report issues immediately. This is a huge time saver and helps narrow down the problematic code early. All results and binaries used during the testing should be preserved so that if any issue if found late in the cycle, it should still be possible to narrow down the problematic build number.
Performance suites take time to evolve but the time spent in putting one together is worth the dividends it pays in the long run.
Profile And Know Your Profiler
Though it may sound simple to narrow down the source and solve a performance issue, it is pretty common practice to use a profiler to determine the bottlenecks in code. The idea is not to jump to the step of profiling without trying to narrow down problems through other means. Once you know you require a profiler, make sure you understand the technique your profiler uses behind the scenes.
Some profilers “instrument” code and insert extra code to collect the timing information. Profilers of this category are accurate for relative comparison but may crash if they do a bad job at instrumenting the code.
Some profilers “sample” the state of the program by collecting the call stack of the program at regular intervals. These profilers indicate the area of the code where the program spends the maximum time without modifying the running program. Here the sample interval and duration of sampling determine the usefulness of the generated profile.
It is important to understand how your profiler collects the data which further aids in its better interpretation.
Conclusion
Performance and profiling do go together but it helps to execute a few steps and to setup some processes in a development cycle that quickly and accurately help in narrowing down the source of the problem.